GC 垃圾回收算法
垃圾回收(Garbage Collection,简称 GC)是自动内存管理的核心机制。本文将深入介绍 GC 的评价标准以及经典的标记-清除算法。
评价标准
评价 GC 算法的性能时,我们采用以下 4 个标准:
| 标准 | 说明 |
|---|---|
| 吞吐量 | 单位时间内的处理能力,即 GC 不占用的时间比例 |
| 最大暂停时间 | GC 执行时程序暂停的最长时间,影响用户体验 |
| 堆使用效率 | 堆空间的有效利用率,避免内存碎片 |
| 访问的局部性 | 相关对象在内存中的邻近程度,影响 CPU 缓存命中率 |
GC 标记 - 清除算法(Mark Sweep GC)
GC 标记 - 清除算法由标记阶段和清除阶段构成。标记阶段是把所有活动对象都做上标记的阶段。清除阶段是把那些没有标记的对象,也就是非活动对象回收的阶段。通过这两个阶段,就可以令不能利用的内存空间重新得到利用。
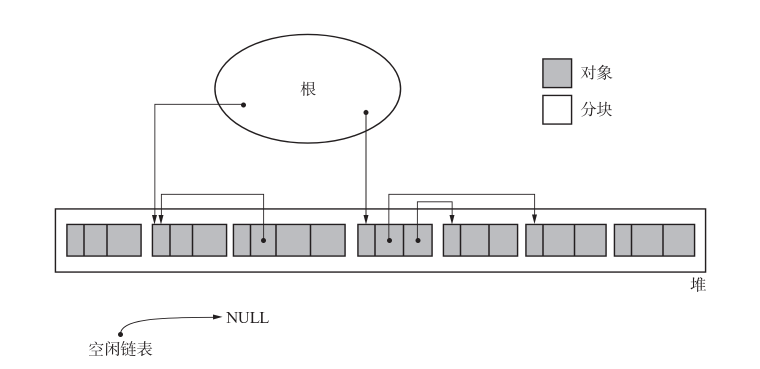
标记阶段
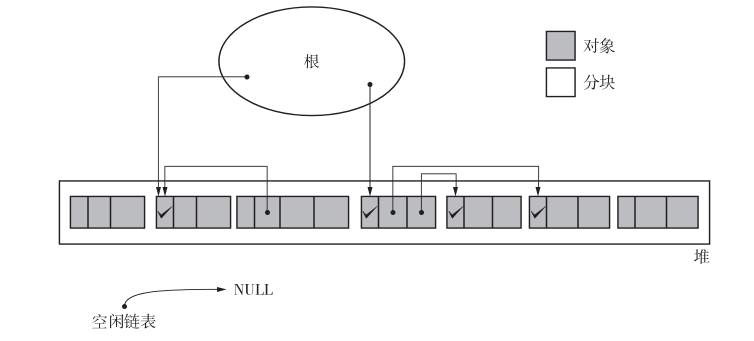
在标记阶段中,collector 会为堆里的所有活动对象打上标记。为此,我们首先要标记通过根直接引用的对象。首先我们标记这样的对象,然后递归地标记通过指针数组能访问到的对象。这样就能把所有活动对象都标记上了。
标记完所有活动对象后,标记阶段就结束了。
深度优先搜索与广度优先搜索
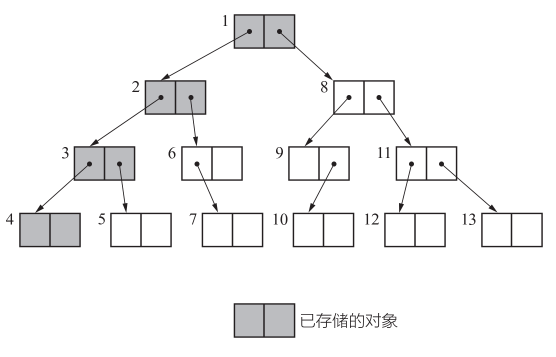
我们在搜索对象并进行标记时使用的是深度优先搜索(depth-first search)。这是尽可能从深度上搜索树形结构的方法。
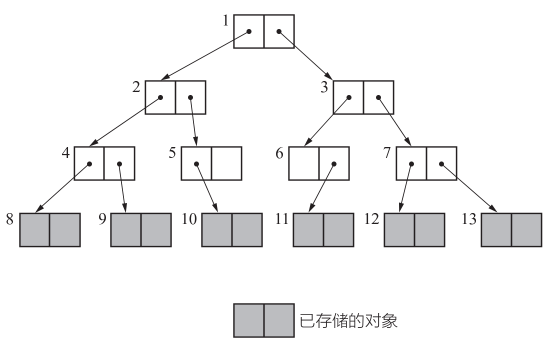
另一方面,还有广度优先搜索(breadth -first search)方法。这是尽可能从广度上搜索树形结构的方法。
GC 会搜索所有对象。不管使用什么搜索方法,搜索相关的步骤数(调查的对象数量)都不会有差别。
另一方面,比较一下内存使用量(已存储的对象数量)就可以知道,深度优先搜索比广度优先搜索更能压低内存使用量。因此我们在标记阶段经常用到深度优先搜索。
清除阶段
在清除阶段中,collector 会遍历整个堆,回收没有打上标记的对象(即垃圾),使其能再次得到利用。
我们必须把非活动对象回收再利用。回收对象就是把对象作为分块,连接到被称为“空闲链表”的单向链表。在之后进行分配时只要遍历这个空闲链表,就可以找到分块了。
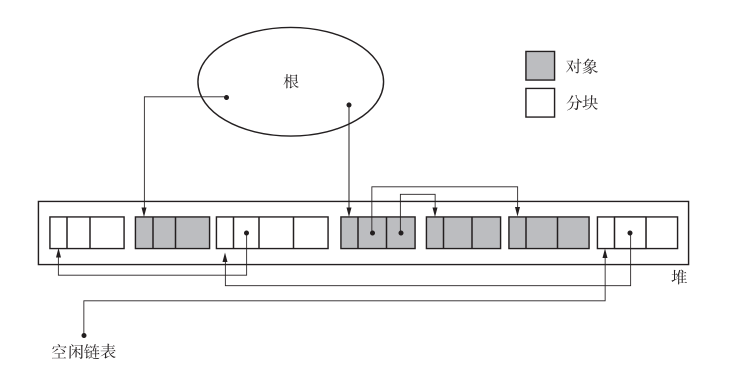
在清除阶段,程序会遍历所有堆,进行垃圾回收。也就是说,所花费时间与堆大小成正比。堆越大,清除阶段所花费的时间就会越长。
分配
如前文所述,我们在清除阶段已经把垃圾对象连接到空闲链表了。搜索空闲链表并寻找大小合适的分块,这项操作就叫作**分配**。
分配策略主要有以下几种:
| 策略 | 说明 | 特点 |
|---|---|---|
| First-fit | 找到第一个足够大的分块就分配 | 速度快,但可能产生碎片 |
| Best-fit | 找到大小最接近的分块 | 空间利用率高,但速度慢 |
| Worst-fit | 找到最大的分块 | 减少小碎片,但大分块消耗快 |
优缺点分析
优点
-
实现简单:标记-清除算法是最基础的 GC 算法,逻辑清晰,容易实现和理解。
-
与保守式 GC 兼容:不需要移动对象,因此可以与不精确的指针识别(保守式 GC)配合使用。
-
不需要额外空间:不像复制算法那样需要双倍的堆空间。
缺点
-
分配速度慢:GC 标记-清除算法中分块是不连续的,因为每次分配都必须遍历空闲链表,找到足够大的分块。最糟糕的情况就是每次进行分配都得把空闲链表遍历到最后。
-
内存碎片化:经过多次分配和回收后,堆中会产生大量不连续的小分块,导致即使总空闲空间足够,也可能无法分配较大的对象。
-
与写时复制不兼容:写时复制技术(copy-on-write)是在 Linux 等众多 UNIX 操作系统的虚拟存储中用到的高速化方法。由于标记阶段会修改对象的标记位,这会触发写时复制,导致内存使用量增加。
-
暂停时间长:标记和清除阶段都需要暂停程序执行(Stop-The-World),堆越大,暂停时间越长。
改进方案
针对标记-清除算法的缺点,业界提出了多种改进方案:
| 改进算法 | 解决的问题 | 原理 |
|---|---|---|
| 标记-压缩 | 内存碎片 | 清除后移动存活对象,消除碎片 |
| 复制算法 | 分配速度、碎片 | 将存活对象复制到新空间 |
| 分代收集 | 暂停时间 | 按对象年龄分代,优先收集新生代 |
| 增量式 GC | 暂停时间 | 将 GC 工作分成多个小步骤 |
| 并发 GC | 暂停时间 | GC 与程序并发执行 |
总结
标记-清除算法作为最经典的 GC 算法,虽然存在分配速度慢、内存碎片化等问题,但它奠定了垃圾回收的理论基础。现代编程语言(如 Go、Java)的 GC 实现都是在此基础上进行优化和改进的。理解标记-清除算法,是深入学习 GC 机制的第一步。